
Hi, I am currently a second year Ph.D. student at Singapore University of Technology and Design (SUTD), co-supervised by Prof. Wei Lu and Prof. Xiaoli Li. I am also a research intern at Tencent HY multimodal RL team, mentored by Dr. Tianyu Pang, working on RL for image/video generation.
In the past, I worked as associate member at Sea AI Lab, and research intern at THUNLP supervised by Prof. Zhiyuan Liu.
My research interests primarily focus on LLM/Diffusion Post-training. I am passionate about developing more effective training strategies to improve the performance of LLMs/Diffusion models.
🔥 News
- 2025.09: 🚀 Released our new paper “Language Models Can Learn from Verbal Feedback without Scalar Rewards” on arXiv! PDF
- 2025.08: 🎉 The paper “Through the Valley …” has been accepted by EMNLP 2025 (main)!
- 2025.01: 🎉 Started my Ph.D. journey at Singapore University of Technology and Design (SUTD) !
- 2024.06: 🎓 Graduated from Beihang University with a Bachelor’s degree in Artificial Intelligence.
- 2024.05: 🎉 Two papers accepted by ACL 2024: OlympiadBench and UltraEval!
📝 Publications
🧠 LLM Reasoning

Language Models Can Learn from Verbal Feedback without Scalar Rewards
Renjie Luo*, Zichen Liu, Xiangyan Liu, Chao Du, Min Lin,
Wenhu Chen, Wei Lu, Tianyu Pang*
- TLDR: 🚀 We show that LLMs can directly learn from verbal feedback — no scalar rewards required.
- Method: We propose the Feedback-Conditional Policy (FCP) — treating feedback as a conditioning signal.
- Offline stage: Learn from response–feedback pairs via simple MLE.
- Online stage: Bootstrap with fresh critiques, refining the policy iteratively.
- Note: This work predates and has been discussed by several recent studies about self-distillation.

Through the Valley: Path to Effective Long CoT Training for Small Language Models
Renjie Luo, Jiaxi Li, Chen Huang, Wei Lu
- TLDR: We reveal the “Long CoT Degradation” phenomenon where small language models (≤3B) suffer performance drops when trained on limited long chain-of-thought data, and propose effective training strategie (via RLVR) to overcome this challenge.

OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Xu Han, et al.
- This work is widely used by RL&Reasoning community, such as SimpleRL-Zoo, Dr.GRPO, Seed 1.5-VL, etc.
⚙️ LLM Evaluation Framework
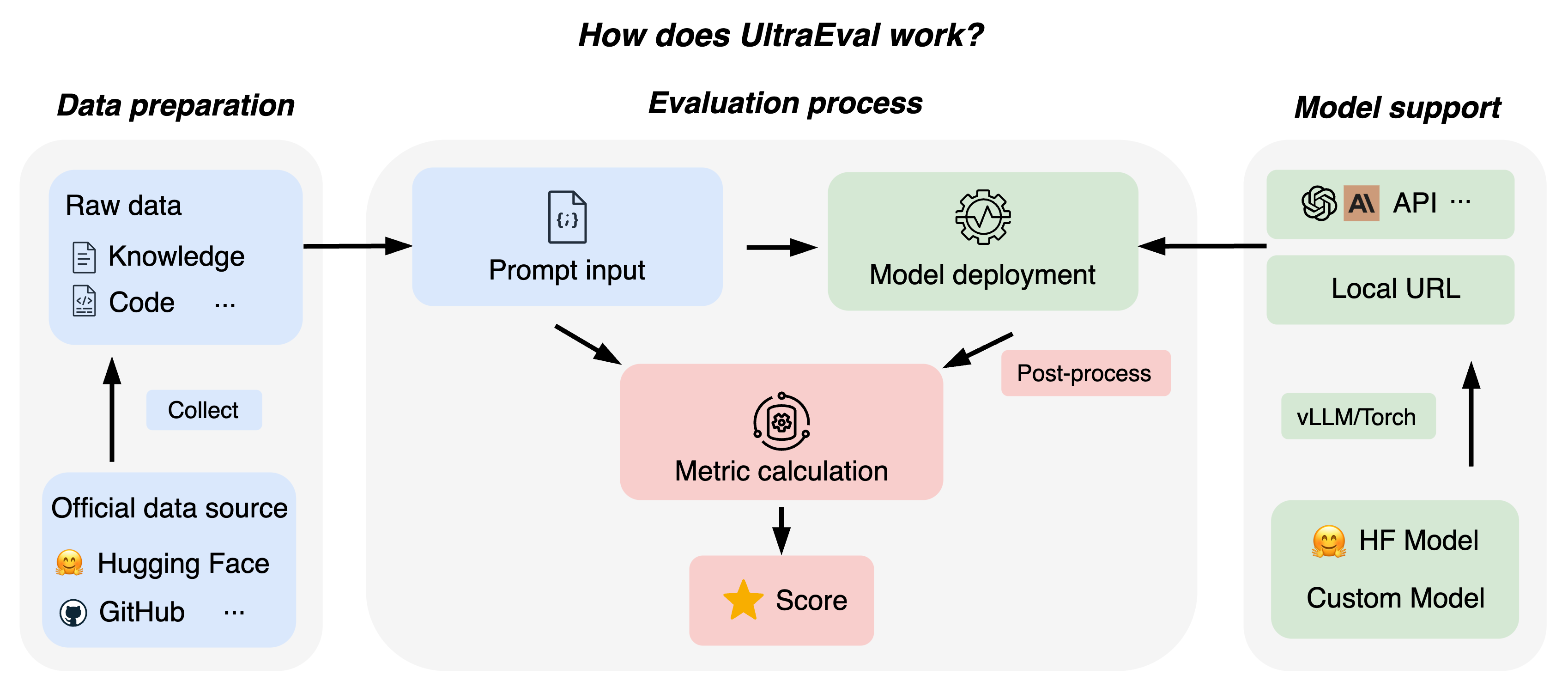
UltraEval: A Lightweight Platform for Flexible and Comprehensive Evaluation for LLMs
Chaoqun He, Renjie Luo, Shengding Hu, Yuanqian Zhao, Jie Zhou, et al.
- Open Source Impact: An automated evaluation framework for large language models, multi-dimensional, with user-friendly and highly customizable evaluation strategies.
- Community Adoption: 200+ stars on GitHub, widely used by researchers for LLM evaluation.
- Comprehensive Features: Supports flexible evaluation strategies with highly customizable pipeline design.
📖 Educations
- 2025.01 - Present, Ph.D. Student, Singapore University of Technology and Design (SUTD), Singapore.
- 2019.09 - 2024.06, Bachelor, Artificial Intelligence, Beihang University, Beijing, China.
💻 Internships
-
2026.02 - current, Tencent HY Multimodal RL Team, Research Intern
-
2025.07 - 2026.02, Sea AI Lab, Associate Member
-
2024.08 - 2024.12, REDnote Inc., Research Intern
-
2023.12 - 2024.08, Natural Language Processing Lab at Tsinghua University (THUNLP), Research Intern
-
2023.06 - 2023.12, ModelBest Inc., Engineer Intern
💬 Languages
- Chinese: Native
- English: Fluent
- Japanese: Intermediate
- Cantonese: Advanced